 Project Overview
Project Overview
Much meta information about sources, such as the semantics of schema
objects, functional dependencies, or relationships between different
data sources, is not always explicitly available for an integration
effort. Often, only the schema is known (or can be queried) and data
can be queried through some kind of interface (e.g. using a query
language such as SQL). However, many other kinds of meta information
about sources are beneficial to perform meaningful information
integration.
One important class of meta information are
constraints that restrict the possible states of an information
source. Such constraints are useful in the determination of
relationships between sources and thus for information
integration. Some integration systems perform a semi-automatic
integration using such constraints. Such approaches, but also
manual or (hypothetical) fully automatic integration systems, would
benefit greatly from the availability of as much meta-information as
possible about the sources to be integrated. The manual search for
such constraints is tedious and often not possible. This is true in
particular when many related information sources are available or when
large relations (with many attributes) are to be compared for
interrelationships. Therefore, the question whether it is possible to
automatically discover meta-information in otherwise unknown
data sources is relevant.
Clearly, the existence of a constraint cannot be inferred from
an inspection of the data, as any suspected constraint may only hold
temporarily or accidentally. However, it is possible to gather
evidence for the existence of a suspected constraint (a process
usually referred to as
discovery) by the determination of
patterns in the data of data sources. The assumption
underlying this discovery is that if a large part of a database
supports a hypothesis about a constraint and there is no evidence to
refute the hypothesis, then this constraint is likely to exist in the
database.
While some types of constraint discovery have been studied to some
extent (for example, functional dependencies and various key
constraints, one important class of constraints, namely inclusion
dependencies, has received little treatment in the literature.
Inclusion dependencies express subset-relationships between databases
and are thus important indicators for redundancies between data
sources. Therefore, the discovery of inclusion dependencies is
important in the context of information integration. While inference
rules on such dependencies have been derived early (for example, by
Casanova (PODS'82) and by Mitchell (PODS'83), the discovery of
inclusion dependencies has not yet been treated thoroughly. A paper by
Kantola (Intl. J. of Inf.Sys. 1992) provides some initial ideas and a
rough complexity bound. It has also been argued in the literature
that a new database normal form based on inclusion dependencies (IDNF)
would be beneficial for some applications. Furthermore, there is some
work on the discovery of related web sites, in which web sites with
their hyperlinks are modelled as graphs.
Description
Inclusion dependencies are rules between two tables 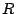 and
and 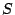 of the
form
of the
form
![$ R[X]\subseteq S[Y]$](img3.gif) , with
, with 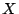 and
and 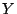 attribute sets. The
discovery of inclusion dependencies is an NP-complete problem, as
KANTOLA et al. [Intl. J. of
Inf. Sys. 1992] have shown. The number of
potential inclusion dependencies between two tables is exponential in
the number of attributes in the two relations, however the number of
interesting inclusion dependencies (i.e., such dependencies that
are not subsumed by others or that actually express some semantic
relationship between tables) is often quite small. Therefore, the
problem of finding those ``interesting'' dependencies is difficult,
but solvable as we will show.
attribute sets. The
discovery of inclusion dependencies is an NP-complete problem, as
KANTOLA et al. [Intl. J. of
Inf. Sys. 1992] have shown. The number of
potential inclusion dependencies between two tables is exponential in
the number of attributes in the two relations, however the number of
interesting inclusion dependencies (i.e., such dependencies that
are not subsumed by others or that actually express some semantic
relationship between tables) is often quite small. Therefore, the
problem of finding those ``interesting'' dependencies is difficult,
but solvable as we will show.
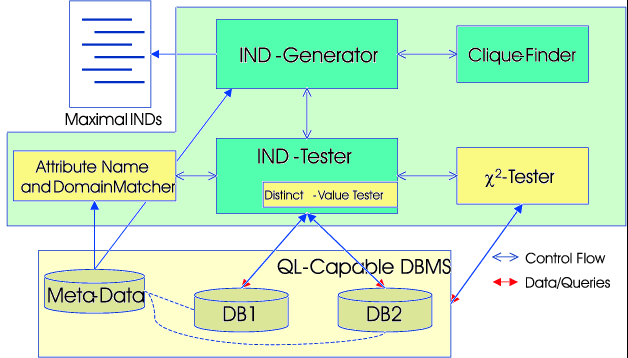
In this dissertation, we propose an automated process for the
discovery of inclusion dependencies in databases under three
assumptions:
- The data model of the databases in question must include the concept of
attributes (``columns'' of data), cannot have complex objects (such as nested
relations), and cannot have pointers or cross-references between data
objects.
- The data sources must provide the names and possibly types of their schema
elements (i.e., the schema must be available).
- The data sources must support the testing of a given
inclusion dependency, for example through some query language.
No further requirements are made of the data sources.
Under these assumptions, our algorithm, named FIND , will discover
inclusion dependencies between two given data sources. Since the
general problem is NP-complete, a full solution cannot always be
found. Therefore, the FIND algorithm will first attempt to discover
all such dependencies, if the problem size is small enough. For
problems that exceed a certain size it will apply heuristics to either
discover the largest inclusion dependency between the data
sources or at least find some large dependency for very large
problems. The algorithm will report whether it has found the complete
or only a partial solution.
, will discover
inclusion dependencies between two given data sources. Since the
general problem is NP-complete, a full solution cannot always be
found. Therefore, the FIND algorithm will first attempt to discover
all such dependencies, if the problem size is small enough. For
problems that exceed a certain size it will apply heuristics to either
discover the largest inclusion dependency between the data
sources or at least find some large dependency for very large
problems. The algorithm will report whether it has found the complete
or only a partial solution.
Our approach uses a mapping of the inclusion dependency discovery
problem to the clique-finding problem in graphs and
k-uniform hypergraphs. As the clique finding problem itself is
also NP-complete, additional heuristics are used when the problem size
exceeds certain limits to restrict the size of the graphs involved and
find a partial or complete solution to the problem.
![[Return to the WPI Homepage]](/dsrg/images/seal.gif)
![[Return to the CS Homepage]](/dsrg/images/new_cs.gif)
![[Return to the DSRG Homepage]](/dsrg/images/dsrg.gif) created by: Andreas Koeller. Last modified
Oct. 31, 2001
created by: Andreas Koeller. Last modified
Oct. 31, 2001