


Next: Conclusions
Up: A Taxonomy of Glyph
Previous: Related Fields
The total number of distinct
views are of N-D data on a 2-D data
space is shown below.
- data-driven (raw):
-
(1 + D)(N2 - N), where D is the number of
distortion techniques (e.g., random jitter, relaxation)
- data-driven (derived):
-
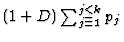 , where k is
the number of distinct derivation algorithms and pj is the number of
variations within algorithm j (e.g., different distance metrics).
, where k is
the number of distinct derivation algorithms and pj is the number of
variations within algorithm j (e.g., different distance metrics).
- structure-driven (linear ordered):
-
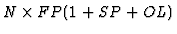 ,
where FP is the
number of filling patterns, SP is the number of methods which introduce
white space for separation (space-padding), and OL is the number of methods
which distort the placement to allow overlaps.
,
where FP is the
number of filling patterns, SP is the number of methods which introduce
white space for separation (space-padding), and OL is the number of methods
which distort the placement to allow overlaps.
How to select? Factors include:
- Characteristics of data (size, distribution)
- the purpose of the visualization (presentation, confirmation, exploration)
- the specific task(s) at hand (e.g., detection, classification, or
measurement of patterns or outliers).
- the skills of the prospective user of the visualization.
- domain knowledge that can lead to "intuitive" mapping
- trade off between efficient screen utilization, the degree of occlusion,
and distortion of the values being used to position the glyph
- whether to impose an implicit structure (what comparison metric to use?)
Next: Conclusions
Up: A Taxonomy of Glyph
Previous: Related Fields
Matthew Ward
1999-02-08