Project
In our society, ranking is a common tool used to prioritize among critical choices impacting people's lives and livelihood, for instance when evaluating people for outcomes like jobs, loans, or educational opportunities. Increasingly for such tasks, the judgments of human analysts are augmented by decision support tools or even fully automated screening procedures which automatically rank candidates. This has prompted significant concern regarding the danger of inadvertently automating unfair treatment of historically disadvantaged groups of people. In addition, there is increasing awareness that unfairness also arises when human analysts make decisions, given we may suffer from implicit bias in our decision making. This interplay of human bias and machine learning now poses additional new challenges regarding fair decision making and with it the design of appropriate bias mitigation technologies.
To tackle this important problem, recent research efforts have began to focus on developing automatic methods for measuring and mitigating unfair bias in rankings. To date, however, these efforts all consider each ranking in isolation. One critical yet overlooked problem is ranking by consensus, where numerous decision makers produce rankings over candidate items, and then those rankings are aggregated to create a final consensus ranking.
Therefore, we propose to model the fair rank aggregation problem with formal constraints that capture prevalent group fairness criteria. This new fairness-preserving optimization model ensures measures of fairness for the candidates being ranked while still producing a representative consensus ranking following the base rankings. We will design a family of exact and approximate bias mitigation solutions to this optimization problem that guarantee fair consensus generation in a rich variety of decision scenarios.
Further, we propose to integrate these fair rank aggregation methods into an interactive human-in-the-loop visual analytics system. This AEQUITAS technology will enable decision makers to collaboratively build fair consensus by leveraging visualization-driven interfaces that aim to facilitate understanding and trust in the consensus building process. AEQUITAS will support comparative analytics to visualize the impact of individual rankings on the final consensus outcome, as well as the trade-offs between accuracy of the aggregation and fairness criteria. Finally, we will conduct extensive user studies to understand how well fairness imposed by the AEQUITAS system aligns with human decision makers' perception of fairness, and the ability of multiple analysts to collaborate effectively using the AEQUITAS technology.
Project Goals:
- Model design for modeling AEQUITAS fair rank aggregation problem.
- AEQUITAS bias mitigation algorithms for fair rank aggregation.
- Optimization strategies supporting interactive fair consensus building.
- Human-in-the-loop visual analytics to enable fair decision making.
- Evaluation of AEQUITAS via experimental studies and design studies.
Research Challenges
The rank aggregation problem is complex. Given a base set of rankings over n items, there are n! possible consensus rankings to chose from. An exhaustive search over all options is thus intractable. Depending on the problem formulation used to determine the consensus ranking, finding the exact solution may be NP-hard. Thus exact solutions typically cannot handle rankings over a large number of items. How best to incorporate contemporary definitions of fairness into this complex problem is an open question.
A solution must balance competing concerns of finding a consensus which represents each of the base rankings equally well, while also ensuring fairness for the candidates being ranked. It remains to be explored whether bias present in the base rankings may be exacerbated by the aggregation procedure, or whether an unintended bias not present in the base rankings may inadvertently be introduced. The difficulty of rank aggregation has been shown to strongly be impacted by the degree to which the base rankings agree on the placement of individual candidates. For our problem of designing practical fair aggregation solutions, it is thus expected that the distribution of groups in the rankings similarly impacts the difficulty of the problem and must be tackled.
While there is major interest recently by the AI community to investigate fair models, many questions remain around the design and the integration of these methods into decision support systems. The use of any single fairness metric or the opaque process to certify fairness may mask discriminatory practices. This risks allowing systems to optimize for only one among possibly many fairness notions while disingenuously introducing other biases. In practice, the formation of aggregated consensus rankings must involve human analysts directly. Therefore, careful evaluation is required to understand whether incorporating bias-mitigation into automated systems will help human analysts make fairer decisions in practice. One key question we propose to study is whether the contemporary fairness definitions we target will match people's perception of fairness. This question has been studied for classification tasks and for individual fairness. However the perception of group fairness in ranking, both with automated systems and when involving human decision makers, remains unexplored.
Building Fair Consensus:
Proposed Interactive Bias Mitigation for Fair Rank Aggregation
To address these challenges, in this project, we propose to design, develop and evaluate a conceptual framework for fair rank aggregation that as foundation seamlessly leverages the popular Kemeny rank aggregation problem formulation. Our preliminary investigation (see Publications) provides us with strong evidence that our proposed framing will enable us to devise effective strategies to mitigate a rich variety of notions of unfair bias, including both statistical parity and error-based criteria.
We propose to develop a family of algorithmic aggregation strategies that model fairness as a constrained optimization problem to tackle the challenge of aggregating a set of rankings generated by a large number of decision makers. In particular, we will study the integration of constraints into integer linear program formulations to balance fairness requirements with aggregation accuracy. Given such solutions when applied to rankings over many items result in a large number of binary variables, we will also investigate the design of optimization strategies, including include fairness-preserving search heuristics, pruning and approximation schemes to efficiently handle large datasets of rankings over many candidates.
Further, we will study the design of a mixed-initiative system, AEQUITAS, that supports human decision makers in interactive fair consensus building. The AEQUITAS system will leverage our fairness-preserving rank aggregation methods both for initial consensus generation as well as during the interactive consensus refinement process. Lastly, we evaluate our battery of alternative fairness-aware rank generation algorithms in a rich test bed of controlled rank aggregation scenarios as well as real world ranking problems such as hiring in a university setting. A series of user studies will engage decision makers in real-world use cases to study human perception of fairness in consensus ranking relative to our proposed metrics of fairness -- along with the support provided by our proposed AEQUITAS technology in empowering decision makers to reach unbiased decisions.
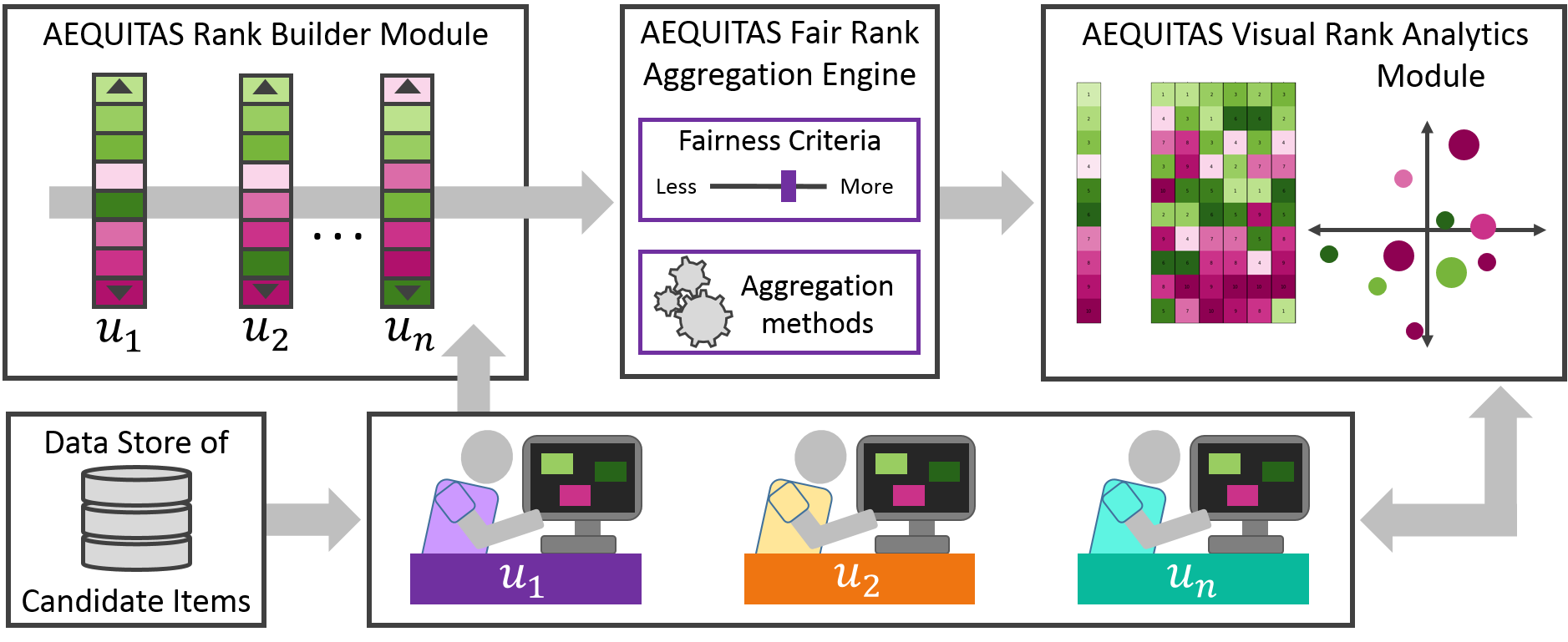
In the figure above we provide an overview of the proposed AEQUITAS system architecture. A rank builder module will allow rankings over candidate items to be created by multiple, possibly distributed, individual decision makers. Then our proposed AEQUITAS bias mitigation algorithms for fair consensus ranking will power the backend fair rank aggregation engine, generating a consensus ranking based on the individual rankings from the decision makers and global criteria for the fairness and aggregation method requirements. Human-in-the-loop interaction will then facilitate each individual decision maker to evaluate their own ranking against the others as well as the generated consensus using novel rank comparison tools via the visual rank analytics module. These AEQUITAS interactive interfaces will enable adjustments to and interactions with the fairness criteria to reveal the trade-off between consensus and fairness for the candidates being ranked.