Our team
Faculty


Dr. Samuel Madden
Professor of Electrical Eng. and Comp. Science
Massachusetts Institute of Technology

PhD Students



Collaborators






Publications
Selected Recent Publications.
- Huayi Zhang. Towards An End-to-End Training Data Management System for Machine Learning Models. Worcester Polytechnic Institution, PhD Dissertation 2023.
- Lei Cao, Yizhou Yan, Samuel Madden, and Elke Rundensteiner. AutoOD: Automatic Outlier Detection, ACM SIGMOD 2022.
- Dennis Hofmann, Peter VanNostrand, Huayi Zhang, Yizhou Yan, Lei Cao, Samuel Madden, and Elke Rundensteiner. A Demonstration of AutoOD: A Self-Tuning Anomaly Detection, VLDB 2022.
- Huayi Zhang, Lei Cao, Samuel Madden, Elke Rundensteiner. LANCET: Labeling Complex Data at Scale, VLDB 2021.
- Huayi Zhang, Lei Cao, Peter VanNostrand, Sam Madden, and Elke Rundensteiner, ELITE: Robust Deep Anomaly Detection with Meta Gradient, ACM SIGKDD 2021
- Huayi Zhang, Lei Cao, Yizhou Yan, Elke Rundensteiner and Samuel Madden, Continously Adaptive Similarity Search, ACM SIGMOD 2020
Funding
We are thankful for the support from NSF for this Outlier Discovery research project. Funding for is also listed on each "Learn More" page.
- NSF 1910880 III-Small: Outlier Discovery Paradigm, Rundensteiner, Elke A. (PI). 2019-present.
- Elke A Rundensteiner (WPI) and Samuel Madden (MIT), “ELEMENTS: Tuning-free Anomaly Detection Service”, NSF 20-592 Cyberinfrastructure for Sustained Scientific Innovation (CSSI), NSF OAC, Collaborative project, 05/01/2021 -- 04/30/2024, $259,651 (Award Number (FAIN): 2103832).
System Releases
An interactive demo of our Automatic Anomaly Detection system is available below. AutoOD is a self-tuning anomaly detection system designed to address the challenges of method selection and hyper-parameter tuning while remaining unsupervised. AutoOD frees users from the tedious manual tuning process often required for anomaly detection by intelligently identifying high likelihood inliers and outliers. AutoOD features a responsive visual interface shown in the screenshots below allowing for seamless user interaction providing the user with insightful knowledge of how AutoOD operates.
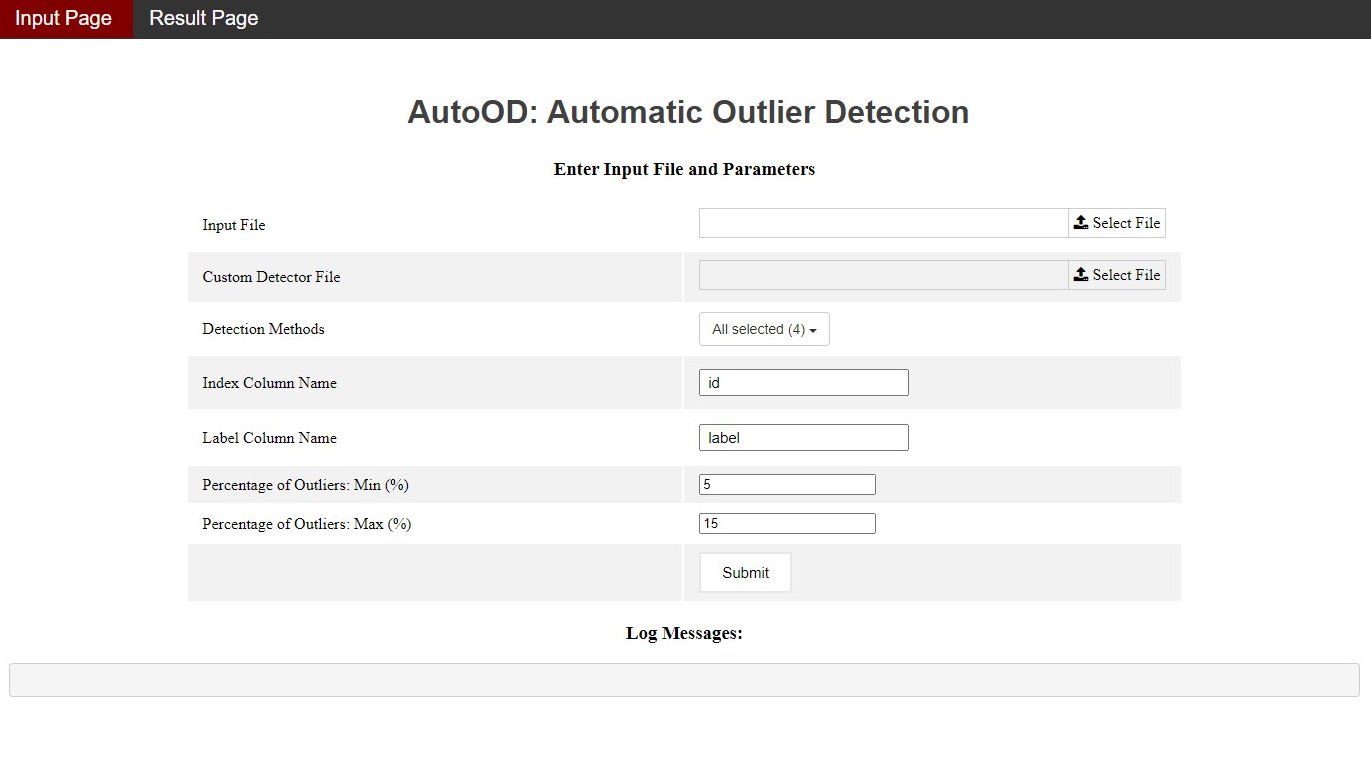
Input Interface
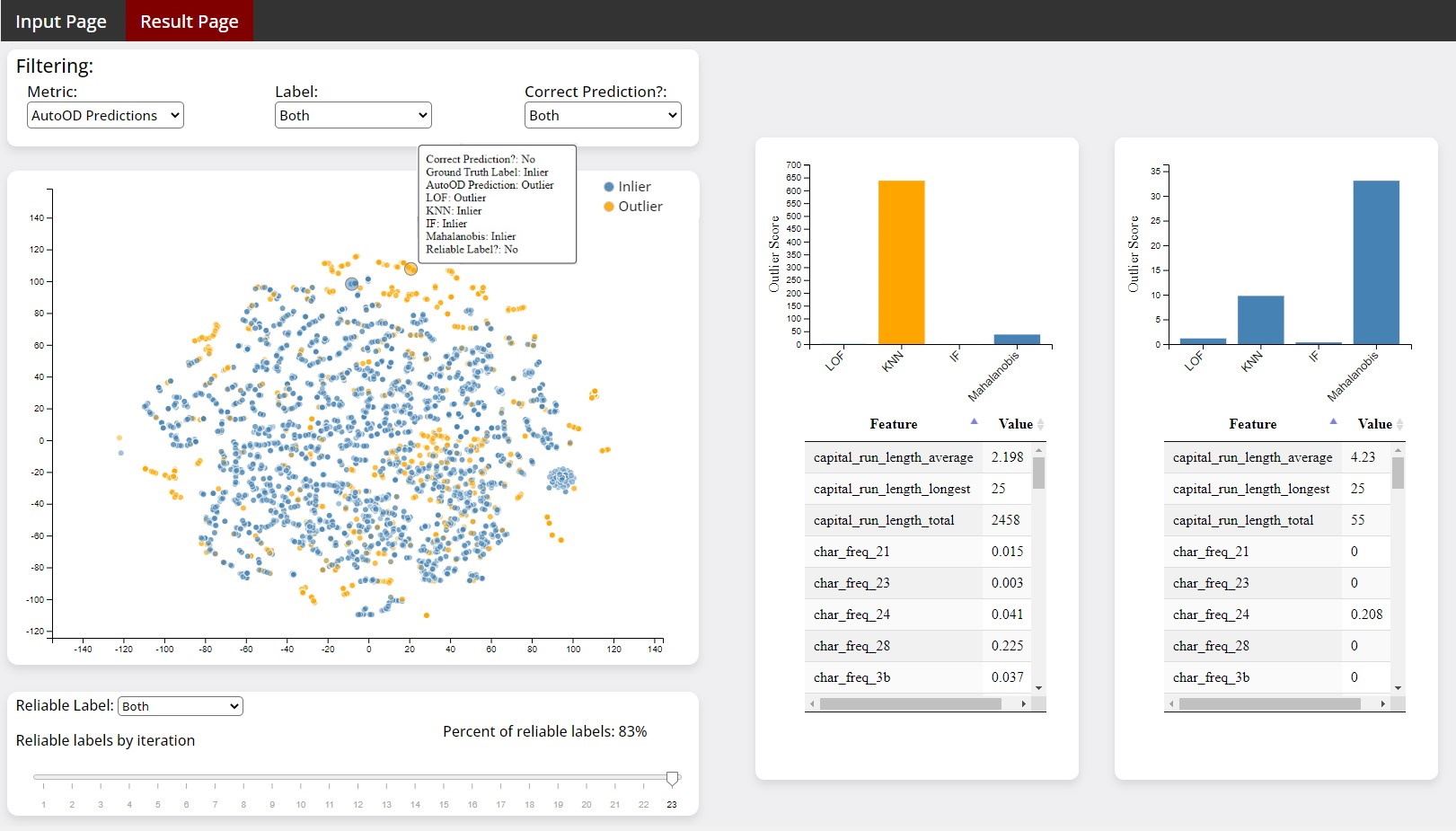
Results Interface
Input Interface: Users can upload data, provide their own anomaly detection methods, specify the column of labels, and customize the expected percentage range of anomalies in their dataset.
Results Interface: Users can filter the chart based on metrics provided and interact with points by hovering over them to view summery statistics. Clicking on a point will provide that respective point's anomaly score for each unsupervised detector and attribute values from the input dataset. In addition, by moving the slider through each iteration, the user can watch the reliable object set change, and at any time select a point to view the contribution of each detector to its status.