Neural networks, by which I mean applications of the computational
model inspired by the human brain, have been given much attention in the
fifty some-odd years since their first conception. In 1943, following
work by Nathan Rashevsky in the 1930's, Warren
McCulloch and Walter Pitts produced a paper on how neurons might work,
using a simple electrical circuit model as a basis for their idea. This
was followed in 1957 by the work of Frank Rosenblatt at Cornell,
who created a hardware network called the Perceptron,
inspired by the operation of the mosquito eye. Following the disillusionment
that resulted from the publication in 1969 of Marvin Minsky and Seymour
Papert's book Perceptrons, which, among other things, showed that
existing techniques could not train networks to solve the simple XOR
problem,
the research area saw a revival in the early 1980s sparked by the work of
Caltech physicist John Hopfield (Dworman98; Latter99).
To date, a number of visualization tools have been developed for
neural networks, the purpose of which is to ease the understanding both
of the learning processes used to train a network and the computation
performed by the network itself. Hinton and Bond diagrams, among the most
basic and popular
techniques, employ simple two dimensional figures that depict the network's
edge weights and, in the case of Bond diagrams, topology. Hyperplane
diagrams and response function plots attempt to display the way in which
each node of a network partitions its multidimensional input
space (Craven91).
Additionally, a number of shareware and commercial programs have been
developed, such as EasyNN (Wolstenholme00), QwikNet (Jensen98),
and Trajan (Hunter99), most of
which employ Bond-like visualizations.
The purpose of this report is to present a new
visualization tool designed to overcome several limitations associated
with existing packages.
In particular, this paper presents the only visualization tool of which I
know that attempts to display the hereditary and geneological relationships
involved in the use of genetic algorithms and evolution strategies to train
neural networks. The goal of this project was to create a tool that would
allow the user to understand how neural networks evolve under a genetic
algorithm, to more quickly and easily solve problems using neural networks,
and to understand the "algorithm" that a specific neural network is using
to solve a problem.
All neural networks consist of a set of
nodes, each of which takes a real-valued input and produces a real-valued
output (also called an activation), and a set of weighted edges
that connect them. The way in which the nodes are connected is a function
of the network architecture, although feedforward networks are the most
common.
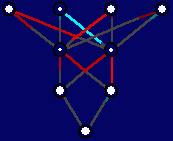
Figure 1.1 to the left of this text (generated using NVIS, the
visualization tool presented in this report)
illustrates a feedforward neural network with 4 "input nodes", 1
"output node", and two hidden layers of 2 nodes each.
The purpose of a neural network is to take a set of inputs, which,
to distinguish them from the real-valued inputs to a single node, we shall
call problem inputs, and produce a set of desired problem
outputs, where each problem input and output
is again a real value. Thus, if the problem inputs consisted of four
real values, we would have four nodes in the input layer, defined as
the set of nodes whose individual inputs are assigned to the problem inputs.
These nodal inputs are processed and passed down through the
hidden layers, and finally to the output layer, whose nodes'
outputs give the final result. An individual node converts its input to
output by means of a layer-specific activation function (also called
a threshold function). The way in which the inputs to the nodes of
one layer are determined from the activations of the nodes in the previous
is described below.
In the figure, the activations are represented by the diameter
of the white circles inside each node, while edge weights are proportional
to the lengths of the colored line segments, with cyan and red indicating
positive and negative sign, respectively. When a neural network is "run",
the outputs from each node in a given layer will be multiplied by the
weights of every edge to which it is attached before being sent over the
edges into the next layer. Thus, for a node with activation 1.5,
with edges of weights 2.0 and -2.0 emanating away from it, the signals
sent across these edges will be 3.0 and -3.0, respectively.
In a feedforward network, the signals always flow from the input
layer toward the output layer, i.e. from top to bottom in the diagram.
Thus, while the inputs to the nodes in the input layer are
the problem inputs themselves, the inputs into the first hidden layer will
be a linear combination of the input layer's outputs. The values for each
layer, therefore, can be determined from the previous layer until the final
(output) layer is reached.
In principle, a feedforward network can compute any computable
function (Sarle99).
With suitable choices of network topology,
activation functions, and edge weights, networks can be created to
find the cosine of an angle, to square real numbers, to determine the
parity of an integer, and to solve a huge variety of input-output mapping
problems.
Common choices for
activation functions include linear, piecewise-linear, hyperbolic tangential,
and sigmoid functions. The network depicted has been trained to produce an
output of 1 if its first two inputs are 1 and 0, and 0 output otherwise.
The activation functions for the four layers of this network are linear,
sigmoid, sigmoid, and linear, respectively.
For more information on neural networks, see the
Neural Network FAQ (Sarle99).