|
|
Dimensional
Stacking
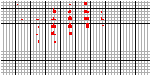
Figure 4
Several recent
techniques have emerged which involve projecting high dimensional
data by embedding dimensions within other dimensions. In
the 1-D case [MIH:91], one starts by discretizing the ranges of
each dimension and assigning an ordering to the dimensions (dimensions
are said to have unique ``speeds''). A background color
is also associated with each speed. The next step is to divide
the screen into C0 vertical strips, where C0
is the cardinality of the dimension with the slowest speed.
The strips are colored according to that speed. Each of
these strips is then divided into C1 strips and colored
accordingly. This is repeated until all dimensions have
been embedded and the data value associated with each cell can
be plotted on the vertical axis.
In 2-D [LEB:90],
an analogous technique called Dimensional Stacking involves
recursively embedding images defined by a pair of dimensions within
pixels of a higher-level image. Unlike the previous system, however,
data is not restricted to functions, thus making this technique
amenable to a wider range of data types. In Worlds within
Worlds [BESHERS:93], each location in a 3-D space may in turn
contain a 3-D space which the user may investigate in a hierarchical
fashion. The most detailed level may contain surfaces, solids,
or point data.
XmdvTool requires
three types of information to project data using dimensional stacking.
The first is the cardinality (number of buckets) for each dimension.
The range of values for each dimension is then decomposed into
that many equal sized subranges. The second type of information
needed is the ordering for the dimensions, from outer-most (slowest)
to inner-most (fastest). Dimensions are assumed to alternate in
orientation. The last piece of information used is the minimum
size for the plotted data item (the system will increase this
value if the entire image can fit within the view area).
Each data point then maps into a unique bucket, which in turn
maps to a unique location in the resulting image. If the
image generated exceeds the size of the view area, scroll bars
are automatically generated to allow panning. A key is provided
in a separate window to help users understand the order of embedding,
and grid lines of varying intensity provide assistance in interpreting
transitions between buckets at different levels in the hierarchy.
The sparseness
of the data set of Figure 1 makes uncovering relationships difficult
using Dimensional Stacking. Figure 4 shows a denser set consisting
of 3-D drill hole data with a fourth dimension representing the
ore grade found at the location (more than 8000 data points).
Longitude and latitude are mapped to the outer dimensions, each
with cardinality 10. Depth and ore grade map to the inner dimensions
(ore grade is the vertical orientation), with cardinality 10 and
5, respectively. There is a clear region in which the ore grade
improves with depth, and other places where digging had stopped
prior to the ore grade falling significantly. By adjusting
the cardinalities and ranges for the various dimensions, a more
detailed view of the data may be obtained [WAR:CGI].
The hierarchical
techniques are best suited for fairly dense data sets and do rather
poorly with sparse data. This is due to the fact that each
possible data point is allocated a specific screen location (with
overlaps avoidable by careful discretization of dimensions), and
as the dimension of the data increases, the screen space needed
expands rapidly. In contrast, the techniques described earlier
generally do well with sparse data over high numbers of dimensions,
though scatterplots are constrained somewhat it the maximum manageable
dimension. The major problem with hierarchical methods is
the difficulty in determining spatial relationships between points
in non-adjacent dimensions. Two points which in fact are
quite close in N-space may project to screen locations which are
quite far apart. This is somewhat alleviated by providing
users with the ability to rapidly change the nesting characteristics
and discretization of the dimensions.
We have extended
flat dimensional stacking to hierarchical dimensional stacking
. In the hierarchical dimensional stacking display, a block within
the extent of a cluster is assigned the color of this cluster.
Its density is determined by the distance between it and the mean
of the cluster, that is, the longer the lighter. Movie
4 is a multiresolutional cluster display of hierarchical dimensional
stacking.
References
[BESHERS:93]:
Beshers, C., Feiner, S.. AutoVisual: rule-based design of
interactive multivariate visualizations. IEEE Computer
Graphics and Applications, Vol. 13, No. 4, pp. 41-49, 1993.
[LEB:90]:
LeBlanc, J., Ward, M.O., Wittels, N.. Exploring N-dimensional
databases. Proceedings of Visualization '90, pp.
230 - 237, 1990.
[MIH:91]:
Mihalisin, T., Gawlinski, E., Timlin, J., and Schwegler, J..
Visualizing multivariate functions, data, and distributions. IEEE
Computer Graphics and Applications, Vol. 11, pp. 28 - 37,
1991.
[WAR:CGI]:
Ward, M.O., LeBlanc, J.T., Tipnis, R.. N-Land: a graphical
tool for exploring N-dimensional data. Proceedings of CG International
'94, 1994.
[WARD:94]:
M. Ward. Xmdvtool: Integrating multiple methods for visualizing
multivariate data. Proc. of Visualization '94, p.
326-33, 1994.
|

{kind=link}